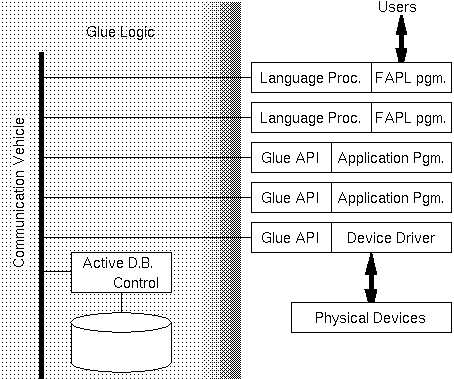
Glue Logic は上図のような構成で用いられる。 図中で Glue Logic は左半分の網を掛けた部分であり、 右側にならんでいるのは Glue Logic の機能を利用する エージェント(アプリケーション・プログラムの実行プロセス)である。
Glue Logic はその上で稼働するエージェント間の通信を中継し、 同時にそれらのエージェントが共有するすべてのデータを一元的に管理する。 これにより、共有データの値が変化すると、 それを通知するメッセージを必要なエージェントに送ることができる。 また、すべてのエージェント間の通信に介在することにより、 エージェント間通信をネットワーク透過とする。 また、アプリケーション・プログラムからは通信相手を仮想化することになり、 ひとつのアプリケーション・モジュールの追加・削除・変更の影響が 他のモジュールの内部に影響を及ぼすことを防ぐことができる。
アプリケーションは、 Glue Logic の API を用いて C などの汎用プログラミング言語を用いて記述するか、 Glue Logic API を内部に持つ FA 用プログラミング言語 (FAPL) によって記述される。 新規アプリケーションは FAPL で記述する方が開発が容易になるが、 既存のソフトウェア資産は Glue Logic API を用いて書き換えることができる。 なお、 FAPL の言語処理系の開発は、 Glue Logic の開発に引き続いて行なう予定である。
プロトタイプ段階で予定されている Glue Logic のインプリメンテーションでは、 下図に示すような サーバ - クライアント・システムの構成をとる。
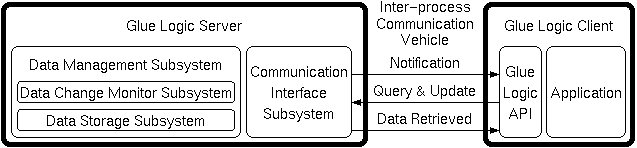
共有データの管理は、 特定のプロセッサ上で稼働する特定のプロセスによって行なわれる。 すなわち、すべてのアプリケーションはこのプロセスとのみ通信を行なう。
Glue Logic のサーバは通信制御サブシステムとデータ管理サブシステムに分けられ、 後者は更にデータ監視サブシステムとデータ保管サブシステムとからなる。 データ保管サブシステムはデータの名前と値との組を保持し、値の参照や変更を行なう。 データ監視サブシステムはあらかじめ指定された名前のデータに変更があった時に 指定していたプロセスにメッセージを送ったり、 変更されたデータに依存する他のデータがある場合には、 依存しているデータの値を再評価する。
上に示したインプリメンテーションでは、 実際の製造現場で要求される冗長性を実現できないため、 コンセプトの実証を行なった後に、 分散データベース・システムを用いて実装を再度行なう予定である。